データパス上のアクティベーターを解明する ¶
公開日:2024-03-20、改訂日:2024-03-22
データパス上のアクティベーターを解明する¶
著者:Stavros Kontopoulos、RedHat プリンシパルソフトウェアエンジニア
このブログ記事では、アクティベーターがデータパス上にあることを認識する方法と、その動作をトリガーする要因について学習します。
Knative サービスは、トラフィックを処理する際に、proxyモードとserveモードの2つのモードで動作できます。プロキシモードの場合、アクティベーターコンポーネントはデータパス上にあり(つまり、着信要求はアクティベーターを経由してルーティングされます)、特定の条件が満たされるまでパス上に残ります(詳しくは後述)。これらの条件が満たされると、アクティベーターはデータパスから削除され、サービスはserveモードに移行します。たとえば、サービスが0から/0にスケールアウト/スケールインする場合、アクティベーターはデフォルトでデータパスに追加されます。このデフォルト設定は、十分な容量が利用可能になるまでアクティベーターがパスから削除されないため、ユーザーを混乱させることがよくあります。これは意図的なものであり、アクティベーターの役割の1つは、バックプレッシャー機能(要求バッファーとして機能)を提供して、Knativeサービスが着信トラフィックで過負荷にならないようにすることです。さらに、Knativeサービスは、アノテーションを使用して、処理できるトラフィック量を定義できます。オートスケーラーコンポーネントは、この情報を使用して、特定のKnativeサービスの着信トラフィックを処理するために必要なポッド数を計算します。
背景¶
Knativeのデフォルトポッドオートスケーラー(KPA)は、ポッドからのメトリクスを使用してスケーリングの決定を行う、高度なアルゴリズムです。新しいKnativeサービスが作成されるときに何が起こるかを詳しく見てみましょう。
ユーザーが新しいサービスを作成すると、対応するKnativeリコンサイラーが、そのサービスのKnativeConfigurationとKnativeRouteを作成します(Knative K8sリソースの詳細についてはこちらを参照)。次に、ConfigurationリコンサイラーがRevisionリソースを作成し、後者のリコンサイラーがサービスのK8sデプロイメントとともにPodAutoscaler(PA)リソースを作成します。Routeリコンサイラーは、クラスタ内でローカルに、そしてクラスタの外部にトラフィックを管理する責任のあるKnative net-*コンポーネントによって取得されるIngressリソースを作成します。
ここで、PAの作成はKPAリコンサイラーをトリガーし、リビジョンにオートスケーリング構成を設定するために特定の手順を実行します。
-
decider.Status.DesiredScaleに初期の目標スケールを保持する内部Deciderリソースを作成し、マルチスケーラーコンポーネントを介してポッドスケーラーを設定します。ポッドスケーラーは2秒ごとに新しいスケール結果を計算し、目標スケールがポッド数と等しくないかどうかという条件に基づいて決定を行います。等しくない場合、KPAリコンサイラーの新しいリコンシリエーションをトリガーします。目標は、KPAが最新のスケール結果を取得することです。 -
メトリクスコレクターコントローラーがリビジョンポッドのスクレーパーを設定するメトリクスリソースを作成します。
-
必要なポッド数を決定し、リビジョンに対応するK8s rawデプロイメントを更新するスケールメソッドを呼び出します。
-
動作モード(プロキシまたはサーブ)に関する情報を保持し、プロキシモードで使用されるアクティベーターの数を格納する
ServerlessService(SKS)を作成/更新します。SKSに指定されたアクティベーターの数は、カバーする必要がある容量によって異なります。 -
PAを更新し、PAのステータスにあるアクティブなポッドと必要なポッドを報告します。
注記
上記のSKS作成/更新イベントは、トラフィックをraw K8sデプロイメントにルーティングできるように、必要な公開および非公開K8sサービスを作成する、その特定のコントローラーからのSKSのリコンシリエーションをトリガーします。また、プロキシモードでは、SKSコントローラーはアクティベーターの数を取得し、リビジョンの公開サービスに等しい数のエンドポイントを構成します。(Ingressリソースによって駆動される)Knativeネットワーキングコンポーネントによって行われたネットワーキング設定と組み合わせて、これはKnativeサービス(ksvc)がトラフィックを提供する準備ができるために必要なエンドツーエンドのネットワーキング設定です。Knativeネットワーキングコンポーネントは、net-istio、net-kourier、net-contour、net-gateway-apiのいずれかになります。
実践における容量と動作モード¶
前述のように、十分な容量が利用可能であれば、アクティベーターはパスから削除されます。この容量がどのように計算されるかを見てみましょう。しかし、その前に、panicウィンドウとstableウィンドウという2つの概念を紹介しましょう。パニックウィンドウとは、トラフィックを処理するのに十分な容量がないことを示す時間の長さです。これは通常、トラフィックの突然のバーストで発生します。パニックモードに入り、パニックウィンドウを開始する条件は次のとおりです。
dppc/readyPodsCount >= spec.PanicThreshold
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
dppcは目標パニックポッド数を表し、パニックモードでオートスケーラーが達成する必要があるものを表します。ターゲット値は、オートスケーラーが目指す同時実行性に関する利用率であり、0.7*(revision_total)として計算されます。Revision totalは、ポッドで許可されるスケーリングメトリクスの最大可能値であり、デフォルトは100(コンテナー同時実行性のデフォルト)です。値0.7は各レプリカの利用率係数であり、それが到達されたときにスケールアウトする必要があります。
注記
KPAメトリックのRequests Per Second(RPS)が使用される場合、利用率係数は0.75です。
observedPanicValueは、パニックウィンドウ中に同時実行性メトリックに対して観測された計算された平均値です。パニックしきい値は設定可能(デフォルトは2)であり、目標ポッドと利用可能なポッドの比率を表します。
パニックモードに入った後、終了するには、安定ウィンドウサイズに等しい期間分の十分な容量が必要です。これは、オートスケーラーが容量を増やすために十分なポッドの準備を試みることも意味します。また、パニックモード以外で動作している場合、オートスケーラーは`dpcc`ではなく、安定期間中のメトリクスに基づいた同様の量`dspc := math.Ceil(observedStableValue / spec.TargetValue)`を使用することに注意してください。
十分な容量の概念を定量化し、トラフィックのバーストに対処するために、非負でなければならない超過バースト容量(EBC)の概念を導入します。これは次のように定義されます。
EBC = TotalCapacity - ObservedPanicValue - TargetBurstCapacity.
`TotalCapacity`は`ready_pod_count*revision_total`として計算されます。デフォルトの`TargetBurstCapacity`(TBC)は200に設定されています。
この時点で、アクティベーターがパスから削除される条件を正式に定義できます。
重要
EBC >= 0 の場合、トラフィックを処理するのに十分な容量があり、アクティベーターはパスから削除されます。
上記のデフォルトと、同時実行メトリクスがカウントされた期間に対して十分な負荷を示すためにリクエストがしばらくの間存在する必要があるという事実を考慮すると、リクエストが非常に迅速に終了するhello-worldの例ではEBC >= 0 を得ることができません。後者は、Knativeサービスがサーブモードにならないように見えるため、初心者にとってしばしば混乱を招きます。次の例では、サーブモードにも移行するKnativeサービスのライフサイクルと、EBCが実際どのように計算されるかを示します。また、この例では、スリープ操作を介してリクエストの存続時間を制御するサンプルアプリを使用しています。セクションAutoscale Sample App - Goを参照してください。したがって、ターゲット同時実行値が10でtbc=10である例のサービスを以下に示します。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: autoscale-go
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/target-burst-capacity: "10"
spec:
containers:
- image: ghcr.io/knative/autoscale-go:latest
これから説明するシナリオは、ksvcをデプロイし、ゼロにスケールダウンしてから、10分間トラフィックを送信するというものです。次に、オートスケーラーからのログを収集し、時間の経過に伴うEBC値、準備完了ポッド、およびパニックモードを可視化します。グラフを次に示します。
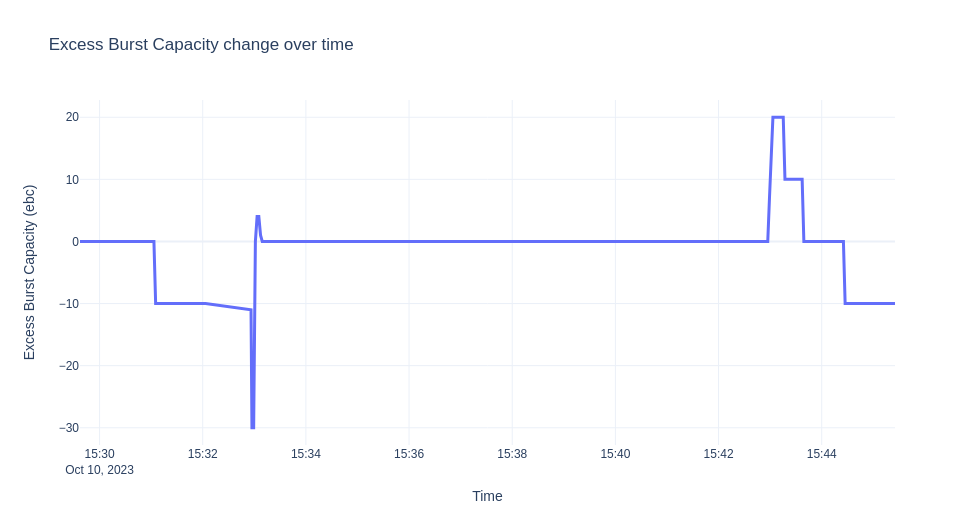
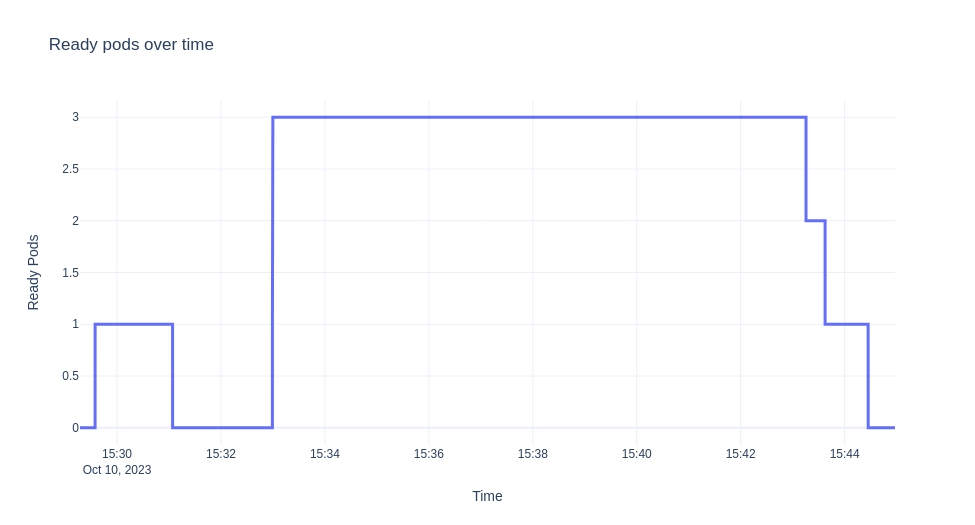
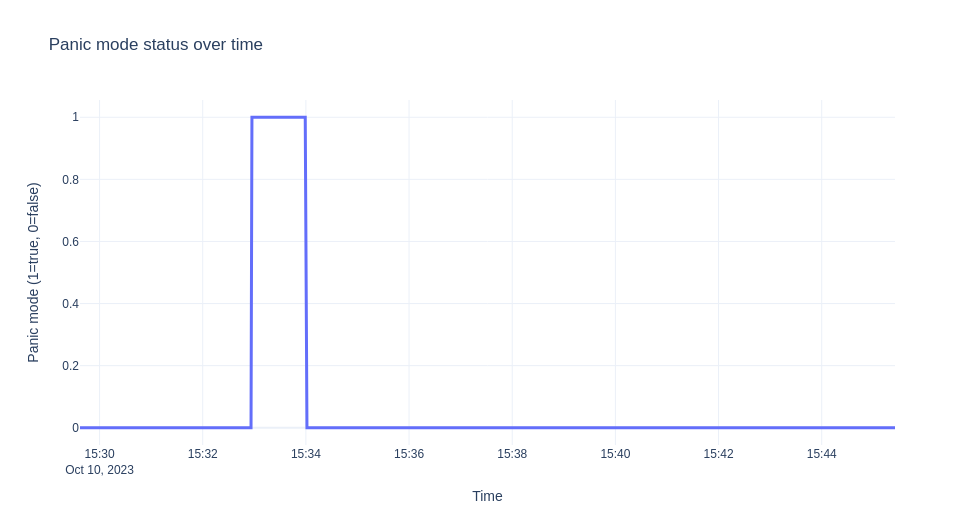
注記
この実験はMinikubeで実行され、トラフィックの生成にはheyツールが使用されました。
上記の状況を詳しく説明しましょう。最初にksvcがデプロイされると、トラフィックがなく、検証のためにデフォルトで1つのポッドが作成されます。
ポッドが起動するまでは、
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Proxy 2 autoscale-go-00001 autoscale-go-00001-private Unknown NoHealthyBackends
$ kubectl get po
NAME READY STATUS RESTARTS AGE
autoscale-go-00001-deployment-6cc679b9d6-xgrkf 2/2 Running 0 24s
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Serve 2 autoscale-go-00001 autoscale-go-00001-private True
サーブモードになっている理由は、EBC=0であるためです。デバッグログを有効にすると、ログに次のように表示されます。
...
"timestamp": "2023-10-10T15:29:37.241575214Z",
"logger": "autoscaler",
"message": "PodCount=1 Total1PodCapacity=10.000 ObsStableValue=0.000 ObsPanicValue=0.000 TargetBC=10.000 ExcessBC=0.000",
EBC = 10 - 0 - 10 = 0
トラフィックがないため、パニックウィンドウまたは安定ウィンドウ中に観測値がないことに注意してください。
トラフィックがないため、ゼロにスケールバックされ、sksはプロキシモードに戻ります。
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Proxy 2 autoscale-go-00001 autoscale-go-00001-private Unknown NoHealthyBackends
トラフィックを送信してみましょう。
hey -z 600s -c 20 -q 1 -host "autoscale-go.default.example.com" "http://192.168.39.43:32718?sleep=1000"
最初にアクティベーターがリクエストを受信すると、オートスケーラーに統計情報を送信し、ある初期スケール(デフォルトは1)に基づいてゼロからスケールしようとしています。
...
"timestamp": "2023-10-10T15:32:56.178498172Z",
"logger": "autoscaler.stats-websocket-server",
"caller": "statserver/server.go:193",
"message": "Received stat message: {Key:default/autoscale-go-00001 Stat:{PodName:activator-59dff6d45c-9rdxh AverageConcurrentRequests:1 AverageProxiedConcurrentRequests:0 RequestCount:1 ProxiedRequestCount:0 ProcessUptime:0 Timestamp:0}}",
"address": ":8080"
十分な容量がないため、オートスケーラーはパニックモードに入ります。EBCは10*0 -1 -10 = -11です。
...
"timestamp": "2023-10-10T15:32:56.178920551Z",
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:286",
"message": "PodCount=0 Total1PodCapacity=10.000 ObsStableValue=1.000 ObsPanicValue=1.000 TargetBC=10.000 ExcessBC=-11.000",
"timestamp": "2023-10-10T15:32:57.24099875Z",
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:215",
"message": "PANICKING."
...
"timestamp":"2023-10-10T15:32:56.949001622Z",
"logger":"autoscaler.stats-websocket-server",
"message":"Received stat message: {Key:default/autoscale-go-00001 Stat:{PodName:activator-59dff6d45c-9rdxh AverageConcurrentRequests:18.873756322609804 AverageProxiedConcurrentRequests:0 RequestCount:19 ProxiedRequestCount:0 ProcessUptime:0 Timestamp:0}}",
"address":":8080"
...
"timestamp":"2023-10-10T15:32:56.432854252Z",
"logger":"autoscaler",
"caller":"kpa/kpa.go:188",
"message":"Observed pod counts=kpa.podCounts{want:1, ready:0, notReady:1, pending:1, terminating:0}",
...
"timestamp":"2023-10-10T15:32:57.241052566Z",
"logger":"autoscaler",
"message":"PodCount=0 Total1PodCapacity=10.000 ObsStableValue=19.874 ObsPanicValue=19.874 TargetBC=10.000 ExcessBC=-30.000",
新しい統計情報に基づいて、kpaはいつか3つのポッドにスケールアップすることを決定します。
"timestamp": "2023-10-10T15:32:57.241421042Z",
"logger": "autoscaler",
"message": "Scaling from 1 to 3",
しかし、なぜそうなるのか見てみましょう。上記のログは、マルチスケーラーから取得されたもので、上記のように報告されたEBCと、さまざまなウィンドウに対する目的のポッド数を示しています。
おおよそ、最終的な目的の数値は、先に見たdppcから導き出されます(コーナーケースをカバーし、最小/最大スケール制限に対してチェックするロジックがさらにあります)。
この場合、ターゲット値は0.7*10=10です。たとえば、パニックウィンドウでは`dppc=ceil(19.874/7)=3`となります。
メトリクスが安定し、リビジョンが十分にスケールアップされると、
"timestamp": "2023-10-10T15:33:01.320912032Z",
"logger": "autoscaler",
"caller": "kpa/kpa.go:158",
"message": "SKS should be in Serve mode: want = 3, ebc = 0, #act's = 2 PA Inactive? = false",
...
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:286",
"message": "PodCount=3 Total1PodCapacity=10.000 ObsStableValue=16.976 ObsPanicValue=15.792 TargetBC=10.000 ExcessBC=4.000",
EBC = 3*10 - floor(15.792) - 10 = 4
必要なポッド数に達し、メトリクスが安定すると、
"timestamp": "2023-10-10T15:33:59.24118625Z",
"logger": "autoscaler",
"message": "PodCount=3 Total1PodCapacity=10.000 ObsStableValue=19.602 ObsPanicValue=19.968 TargetBC=10.000 ExcessBC=0.000",
数秒後、パニックモードになってから1分後に、安定モード(パニック解除)になります。
"timestamp": "2023-10-10T15:34:01.240916706Z",
"logger": "autoscaler",
"message": "Un-panicking.",
"knative.dev/key": "default/autoscale-go-00001"
十分な容量があるため、`sks`も`serve`モードに移行します。トラフィックが停止し、デプロイメントがゼロにスケールバックされるまで(アクティベーターはパスから削除されます)。上記の実験では、ほぼ10分間安定したトラフィックがあるため、十分なポッドの準備が整うとすぐに変更は観察されません。トラフィックが減少してポッド数を調整するまで、短時間、必要なよりも多くの`ebc`があります。
主要なイベントも次のタイムラインに示されています。
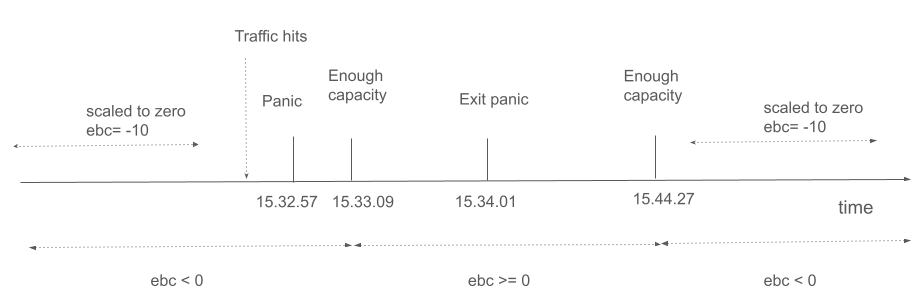
結論¶
サービスがプロキシモードで停止する理由や、アクティベーターがデータパス上にある場合にユーザーがアクティベーターを管理する方法がよくわかりません。これは、特にKnative Servingを初めて使用する際に重要です。上記の詳しい例により、Servingデータプレーンのこの基本的な動作を解明できたことを願っています。